Build a JSON response directly in PostgreSQL
Introduction
Anyone involved in web or back-end development had to create an API service at some point that outputs data from a database in a JSON format. A typical database-centric service does more or less 3 things:
- Query the data
- Transform it to the required format
- Send it over the wire
Looks simple, right? But there is a lot more going on just to deliver some data stored in the database.
The Problem
Multiple steps
Once you query the database, you need to deserialize it’s result into some data structure or an object (or a set of objects) that you can later use to access or to manipulate the data. If there is a mismatch between the structure of the data and the structure of the response, you need to produce another set of objects from the first ones to create the response. Then you need to serialize them, this time in a JSON format, and then send the JSON string over the wire. That is one deserialization, one serialization, and several memory allocations in between.
If you happen to use a dynamically typed language, you could probably get away with manipulating some hash maps and/or arrays and call it a day. If you happen to use a statically typed language, you’ll likely need types declared for both the data model and the response, and maybe even some transitional types.
ORMs and query builders
Things can get even more wasteful (not to mention slow) when using these tools, even if one uses them carefully. You may not care about that and enjoy your convenience, but here are some of the things that happen when querying data with them:
- In an ORM, a model corresponds to a database table and contains the same fields as the table. So every time you query with this model, you’ll get all the fields from the table even if you don’t need them. And in case there is a way to select only the fields you need, you’ll end up with an inconsistent model to work with.
- Related models are retrieved in two ways: either with joins or with separate queries.
When using joins, number of records are multiplied with the number of records found in the joined table, containing the data from both. More joins, more multiplications. And if you happen to use cross join, you’ll end up with a cartesian product of records. Combine that with 1. and that’s a lot of redundant data to be pulled into memory. It then iterates through the result set in order to produce objects as defined in the model. That means more processing and more memory allocation.
Using separate queries does not require as much memory or processing time, but it does require additional network hops to the database, waiting for it’s result, and deserializing it into a usable structure.
The Solution
What if I tell you that there is a way avoid all this cruft and tap the response directly from the data source? After all, database systems are not just storage, they are systems (the S in RDBMS), which means they are capable of doing much more than just to store and retrieve the data. And the one we’re talking about here is a quite powerful one: PostgreSQL.
PostgreSQL and JSON
PostgreSQL supports JSON as a data type since version 9.4 released in 2014, allowing for more flexible storage needs. But it’s not just storing and searching of JSON as is, there are plenty of functions and operators you can use to create, modify, assert or aggregate JSON objects and arrays right in the SQL query. It does have some limitations, but it’s quite useful nevertheless.
There are two types used for JSON: JSON and JSONB. The former is essentially a text that has to be parsed every time when operated on it, while the latter is a binary-optimized type that is faster to access and operate on, and a recommended type to store JSON.
An example
For an example I’ll use a relation similar to the one I’ve encountered recently: let’s imagine we have two tables called folder and document in a relation 1:n, where every document belongs to some folder. A single folder has different settings stored as a JSON object, and an array of named web links also stored as JSON. A document contains some key-value properties that is, as you can imagine, also stored as JSON.
An API service to get details of a single folder needs to return all available columns, only a subset of it’s settings, and also all of it’s documents as an array under documents key.
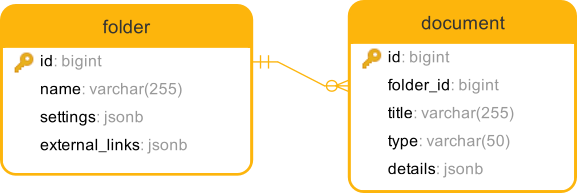
An example schema
Folder settings look like this:
{
"qr_size": 200,
"qr_color": "#4d00a7",
"folder_color": "#4d00a7",
"show_label": true,
"qr_bg_color": "#ffffff",
"alert_on_visit": false
}Folder external links look like this:
[
{
"id": "4cb41be0-ad12-4161-83cb-02c159801be8",
"link": "https://www.google.com",
"type": "web",
"label": "Google"
}
// maybe more links
]Document details look like this:
[
{
"id": "b6f9fe23-d4d6-4a61-b01a-934f3dd61a5e",
"mask": "abc***xyz",
"name": "field name",
"value": "field value"
}
// maybe more details
]Note how the elements of an array have a generated id field, so that the UI app could manage the elements properly, but it should not be included in the response. Also note the mask field in the document details, which will be addressed later.
Writing the query
Let’s write the query without including the documents first:
select
json_build_object('data',
json_build_object(
'id', f.id,
'name', f.name,
'settings', json_build_object(
'alert_on_visit', f.settings -> 'alert_on_visit',
'folder_color', f.settings -> 'folder_color'
),
'external_links', (select json_agg(el - 'id')
from jsonb_array_elements(f.external_links) el)
)
)
from folder f
where f.id = $1Used functions and operators explained:
json_build_objectis, obviously, a function to build JSON object by giving it an even number of variadic arguments, alternating key and the value->is an operator to extract a field from a JSON object as is, whereas->>extracts value as textjsonb_array_elementsexpands a top-level JSON array (stored as JSONB, note the prefix jsonb_) into a set of JSON values, so that set operations likeselectcan be used-is an operator that removes a key (and it’s value) from the JSON objectjson_aggis an aggregate function that collects the input values (including NULL) into a JSON array, converting values to JSON
Now that we understand the basic building blocks, let’s add the documents as well:
select
json_build_object('data',
json_build_object(
'id', f.id,
'name', f.name,
'settings', json_build_object(
'alert_on_visit', f.settings -> 'alert_on_visit',
'folder_color', f.settings -> 'folder_color'
),
'external_links', (select json_agg(el - 'id')
from jsonb_array_elements(f.external_links) el),
'documents', (
with doc as (
select id, title, type, details from document
where folder_id = f.id
order by id desc
)
select
json_agg(json_build_object(
'id', doc.id,
'title', doc.title,
'type', doc.type,
'details', (select
json_agg(json_build_object(
'name', dd ->> 'name',
'value', dd ->> 'value'
)) from jsonb_array_elements(doc.details) dd)
))
from doc
)
))
from folder f
where f.id = $1Here we are using a CTE to fetch and sort the documents in a required order, and then build the JSON array with the aggregate function.
Now that we have the query, what’s left is to make a web request handler that will execute it and pipe its response as a HTTP response.
If you are using Go for example, an HTTP handler could look like this:
func folderGetHandler(http.ResponseWriter, *http.Request) {
// fetch the db connection, query, and the folder id
// ...
row := db.QueryRow(query, folderId)
var s string
if err := row.Scan(&s); err != nil {
server.NotFoundResponse(w, r)
} else {
w.Header().Set("content-type", "application/json")
w.Write([]byte(s))
}
}And a sample response:
{
"data": {
"id": 3,
"name": "sample3",
"settings": {
"alert_on_visit": false,
"folder_color": "#000000"
},
"external_links": [
{
"link": "https://www.example.com/pay?id=3",
"type": "payment",
"label": "Pay online"
},
{
"link": "name@example.com",
"type": "email",
"label": "Agent"
}
],
"documents": [
{
"id": 7,
"title": "Sample Policy",
"type": "correction",
"details": [
{
"name": "Detail 1",
"value": "New value 1"
}
]
},
{
"id": 6,
"title": "Sample Policy",
"type": "policy",
"details": [
{
"name": "Detail 1",
"value": "Value 1"
},
{
"name": "Detail 2",
"value": "Value 2"
}
]
}
]
}
}Summary
Now compare the code above with what is usually required to make such a service. With a somewhat larger SQL query we avoid:
- Serialization and deserialization of data into objects and back. Only the response text needs to be decoded.
- Joins with related tables
- Additional calls to the database
- Redundant data delivered over the network, or processed anywhere within the app
- Additional types declared
- Having to edit on multiple places to change the response structure
And with proper indexing of tables, the response time will be noticeably shorter.
Some challenges
As you may have expected, cutting through all these layers of abstraction does introduce some additional challenges when it comes to making the design decision. Below are some of them.
Data outside the database
Perhaps not all of the data you need to return is stored in the database. Some of it can live i.e. in the user session, or some shared resource.
If the amount of such data is small, it can be made as a part of the query, and have the database return it back as a part of the response. Larger samples could require some string building and concatenation, which isn’t exactly a favorable thing. But if a significant portion of response data is not in the database, then this approach isn’t suitable and could become a source of trouble more than it’d be beneficial.
Custom transformations
Remember the mask field in the document details that I’ve mentioned to take note in the example above? The requirement that wasn’t addressed in the example was to mask the value by one of the predefined patterns, which is the value of the mask field. So, should we just drop all of this and go the usual way just for one small transformation? Not necessarily. The transformation is a simple function without side effects (pure), and could be easily written as a PL/pgSQL function:
create or replace function mask_detail(mask text, v text)
returns text
language plpgsql
immutable
parallel safe
returns null on null input
as
$$
declare
output text;
len int;
begin
output = trim(v);
len = length(output);
case mask
-- mask middle text
when 'abc***xyz' then
case
when len > 6 then
output = substring(output, 1, 3) || '***' || substring(output, len - 2, 3);
when len = 6 then
output = substring(output, 1, 1) || '***' || substring(output, len - 1, 2);
when len > 1 then
output = substring(output, 1, 1) || '***' || substring(output, len, 1);
when len = 0 then
output = '';
else
output = substring(output, 1, 1) || '***';
end case;
-- other cases omitted for clarity
else
return output;
end case;
return output;
end;
$$Now the document detail subquery could look like this:
select json_agg(json_build_object(
'name', dd ->> 'name',
'value', mask_detail(dd ->> 'mask', dd ->> 'value')
)) from jsonb_array_elements(d.details) ddAll of this means that you might need to offload some data specific code to the database layer too, not just the creation of the response. If you don’t like the idea of code spreading to the database (that you manage through a migration system just like the tables), then this approach will hardly resonate with you.
On the other hand, it’s not uncommon to have an application consisted of multiple services doing different things, so you could think of PostgreSQL as another service you communicate with through an RPC API that parses SQL instead of protobuf or JSON.
Dynamic queries
A reasonable question at this point is: How do I make the queries dynamically? Don’t tell me I need to concat SQL strings like in the early days of PHP?
Building queries with string concatenation is bad indeed - it hurts readability and it’s prone to errors. With ORMs out the window, what really is there for us? And since the queries we’ll be writing are a bit longer than usual, the solution I’m going to propose is the same one that people created in order not to concatenate strings to produce HTML: a template language.
It could be any established template language that has the following properties:
- It has a syntax that is easy to spot in the text. The ones based on using braces will probably fit.
- It is fast to parse, or it has a caching mechanism so that parsed templates could be reused multiple times.
I tried this with Go’s text/template and embedding the files with embed directives, and so far I don’t hate it (but could use a better editor support though). Note that you don’t need Go for this, you could try something similar with Twig, Liquid, Mustache or basically any other template language you see fit.
To see how it looks, have a peek at this example, where the user data linked to the folder is optional:
select
json_build_object('data',
json_build_object(
'id', f.id,
'name', f.name,
'settings', json_build_object(
'alert_on_visit', f.settings -> 'alert_on_visit',
'folder_color', f.settings -> 'folder_color'
),
{{if .ShowUser}}
'user_name', u.name,
'user_profile', u.profile,
{{end}}
'external_links', (select json_agg(el - 'id')
from jsonb_array_elements(f.external_links) el)
)
)
from folder f
{{if .ShowUser}}
inner join public.user u on u.id = f.user_id
{{end}}
where f.id = $1Not ideal, but arguably better than concatenation. And you have all the power of SQL at your fingertips.
Conclusion
By presenting this idea, I hope I’ve nudged you further into exploration of what your tools at hand can do to make things simpler and faster. It’s easy to stick to the “lowest common denominator” design, a “we’ve always done it this way” mindset, and, figuratively speaking, dispose many useful things to the attic to collect dust just because you’re not sure if you should use them. And as a true engineer, always do the cost-benefit analysis of every idea in the given context.