Формирај JSON одговор директно у PostgreSQL-у
Увод
Свако ко се бавио са веб или серверским развојем је у неком тренутку морао да направи API сервис који доставља податке из базе података у JSON формату по некој структури. Типичан овакав сервис ради више-мање 3 ствари:
- Шаље упит на базу и чита резултате
- Трансформише податке у тражени формат
- Враћа одговор
Дјелује једноставно, зар не? Али ту се дешава много више ствари испод хаубе, само да би се доставили некакви подаци из базе.
Проблем
Вишеструки кораци
Након што се добије резултат упита на базу, потребно га је десеријализовати у некакву структуру података или објекат (или скуп објеката) који се касније могу искористити за приступ подацима или њихову модификацију. Уколико постоји неслагање између структуре података у бази и структуре одговора који сервис враћа, потребно је креирати још један скуп објеката од првобитног скупа како би се добио одговор. Затим је потребно серијализовати нови скуп објеката, овај пут у JSON формат, и послати стринг као одговор. То је једна десеријализација, једна серијализација, и вишеструко алоцирање меморије између.
Уколико се користи језик са динамичким типовима, вјероватно је могуће проћи са манипулацијом хеш мапи и/или низова и завршити посао. А ако је у питању језик са статичким типовима, вјероватно би било потребно дефинисати типове за модел података, за одговор, а можда и некакве прелазне типове потребне у процесу.
ORM-ови и ”градитељи упита”
Ствари могу да постану још растрошније (да не спомињем и спорије) када се користе ови алати, чак и када се користе опрезно. Можда те то не занима и важнија ти је погодност кориштења, али ево пар ствари које се дешавају када се користе ови алати за упите на базу:
- У ORM алату, модел (класа) одговара табели у бази, и садржи сва поља као и табела. Сваки пут када се креира упит са овим моделом, извлаче се подаци из свих колона табеле, чак и када нису потребни. У случају да постоји начин да се селектују само нека од поља, добија се модел који није конзистентан.
- Модели који су у вези са првобитним добијају се на два начина: или са спајањима (joins) или засебним упитима.
Када се користи спајање, број добијених уписа се мултиплицира са бројем уписа из везне табеле, и сваки ред садржи податке из обе табеле. Више операција спајања, више мултиплицирања редова. А ако се користи cross join, резултат је декартов производ уписа. Комбинујући ово са чињеницом под 1., то је много редундантних података које је потребно доставити преко мреже и смјестити у меморију. Затим је потребно проћи кроз све те редове како би се креирала структура дефинисана моделом података, што значи додатно вријеме за обраду и додатне алокације меморије.
Кориштење засебних упита не захтјева толико меморије или времена за обраду, али захтјева додатне мрежне скокове према бази података, чекање на њен одговор, и десеријализацију одговора у корисну структуру.
Рјешење
Шта ако је могуће пресјећи кроз све ове слојеве и добити одговор директно са извора података? Ипак, системи база података нису само мјесто за податаке, то су системи (С у СУБП), што значи да њихове могућности превазилазе пуко смјештање и добављање података. А систем о коме је овде говоримо је врло моћан: PostgreSQL.
PostgreSQL и JSON
PostgreSQL подржава JSON као тип података од верзије 9.4 пуштене 2014, и тако омогућио флексибилније начине чувања података. Али није у питању само чување и претраживање JSON података, постоји много функција и оператора који се могу искористити за креирање, модификацију, тестирање или агрегирање JSON објеката и низова директно као резултат SQL упита. Иако постоје одређена ограничења, корисност ове функционалности је неупитна.
Постоје два типа која се користе за JSON: JSON и JSONB. Први је у суштини текст који је потребно парсирати сваки пут кад се оперише над њим, док је други бинарно оптимизован за бржи приступ и операције над подацима, и генерално се препоручује као тип за чување у бази.
Примјер
Као примјер ћу да искористим релацију сличну једној са којом сам се сусрео недавно: замислимо да имамо двије табеле назване folder и document, а које су у релацији 1:н, гдје сваки документ припада неком фолдеру. Сваки фолдер има своја подешавања која се чувају као JSON објекат, и има низ именованих веб линкова који се такође чувају као JSON. Документ садржи детаље који се презентују као кључ-вриједност, а који се такође, наравно, чувају као JSON.
API сервис који добаља детаље неког фолдера мора да врати све доступне колоне фолдера, подскуп његових подешавања, али и све његове документе као низ под documents атрибутом.
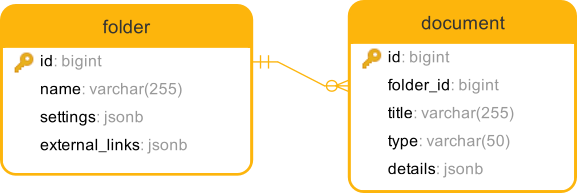
Шема
Подешавања фолдера изгледају отприлике овако:
{
"qr_size": 200,
"qr_color": "#4d00a7",
"folder_color": "#4d00a7",
"show_label": true,
"qr_bg_color": "#ffffff",
"alert_on_visit": false
}Екстерни веб линкови изгледају овако:
[
{
"id": "4cb41be0-ad12-4161-83cb-02c159801be8",
"link": "https://www.google.com",
"type": "web",
"label": "Google"
}
// можда још линкова
]Детаљи документа изгледају овако:
[
{
"id": "b6f9fe23-d4d6-4a61-b01a-934f3dd61a5e",
"mask": "abc***xyz",
"name": "име поља",
"value": "вриједност поља"
}
// можда још детаља
]Примјетимо како елементи низова имају генерисано id поље, како би кориснички дио апликације адекватно управљао са њима. Али они не треба да буду укључени у одговор. Такође примјетимо поље mask у детаљима документа, на које ћемо се вратити касније.
Писање упита
Прво напишимо упит без укључивања докумената:
select
json_build_object('data',
json_build_object(
'id', f.id,
'name', f.name,
'settings', json_build_object(
'alert_on_visit', f.settings -> 'alert_on_visit',
'folder_color', f.settings -> 'folder_color'
),
'external_links', (select json_agg(el - 'id')
from jsonb_array_elements(f.external_links) el)
)
)
from folder f
where f.id = $1Објашњења кориштених фукција и оператора:
json_build_objectје, очигледно, функција за креирање JSON објекта тако што јој се прослиједи промјенљив, али паран број аргумената, смјењујући кључ и вриједност наизмјенично->је оператор за екстрактовање вриједности из JSON објекта под неким кључем у оригиналној верзији, док оператор->>екстрактује вриједност као текстjsonb_array_elementsпроширује JSON низ (чуван као JSONB, примјетимо префикс jsonb_) у скуп JSON вриједности, како би се операције над скуповима попутselectмогле да користе-је оператор којим се уклања кључ (и вриједност под њим) из JSON објектаjson_aggје агрегатна функција која скупља улазне вриједности (укључујући NULL) у JSON низ, при том конвертујући вриједности у JSON
Сада када разумијемо основне градивне јединице, додајмо и подупит за документе:
select
json_build_object('data',
json_build_object(
'id', f.id,
'name', f.name,
'settings', json_build_object(
'alert_on_visit', f.settings -> 'alert_on_visit',
'folder_color', f.settings -> 'folder_color'
),
'external_links', (select json_agg(el - 'id')
from jsonb_array_elements(f.external_links) el),
'documents', (
with doc as (
select id, title, type, details from document
where folder_id = f.id
order by id desc
)
select
json_agg(json_build_object(
'id', doc.id,
'title', doc.title,
'type', doc.type,
'details', (select
json_agg(json_build_object(
'name', dd ->> 'name',
'value', dd ->> 'value'
)) from jsonb_array_elements(doc.details) dd)
))
from doc
)
))
from folder f
where f.id = $1Овде је искориштен CTE како би се добили и сортирали документи у траженом редослиједу, а затим се од њих креира JSON низ помоћу агрегатне функције.
Сада када имамо упит, још је преостало да креирамо код који прихвата веб захтјев, извршава упит и просљеђује одговор без обраде.
Ако користимо нпр. Go, HTTP ”руковалац” би могао да изгледа овако:
func folderGetHandler(http.ResponseWriter, *http.Request) {
// добавити конекцију на базу, упит и број фолдера
// ...
row := db.QueryRow(query, folderId)
var s string
if err := row.Scan(&s); err != nil {
server.NotFoundResponse(w, r)
} else {
w.Header().Set("content-type", "application/json")
w.Write([]byte(s))
}
}А ево и примјер одговора:
{
"data": {
"id": 3,
"name": "sample3",
"settings": {
"alert_on_visit": false,
"folder_color": "#000000"
},
"external_links": [
{
"link": "https://www.example.com/pay?id=3",
"type": "payment",
"label": "Pay online"
},
{
"link": "name@example.com",
"type": "email",
"label": "Agent"
}
],
"documents": [
{
"id": 7,
"title": "Sample Policy",
"type": "correction",
"details": [
{
"name": "Detail 1",
"value": "New value 1"
}
]
},
{
"id": 6,
"title": "Sample Policy",
"type": "policy",
"details": [
{
"name": "Detail 1",
"value": "Value 1"
},
{
"name": "Detail 2",
"value": "Value 2"
}
]
}
]
}
}Резиме
Упоредимо код изнад са оним који би се иначе користио за овакве сервисе. Са нешто дужим SQL упитом избјегавамо:
- Серијализацију и десеријализацију података у објекте и обратно. Само текст треба да се декодује.
- Спајање са везним табелама
- Додатне позиве на базу
- Достављање редундантних података преко мреже, као и њихово процесирање било гдје у апликацији
- Дефинисање додатних типова
- Потребу за едитовањем на више мјеста како би се измјенила структура одговора
А уз адекватно индексирање табела, вријеме одзива сервиса ће да буде примјетно краће.
Изазови
Као што се може да се наслути, уклањање низа слојева апстракције на овај начин доноси и одређене изазове које је потребно узети у обзир приликом доношења одлуке о дизајну. Испод су наведени неки од њих.
Подаци изван базе података
Можда се подаци које је потребно вратити у одговору не налазе сви у бази података. Неки од њих могу да се налазе нпр. у корисничкој сесији, или у неком дјељеном ресурсу.
Ако је количина тих података мала, онда би могли да се начине као дио упита, и затим их добити назад као дио одговора. Веће количине би вјероватно захтјевале обраду или спајање текста, што није баш погодно ни препоручљиво. Али ако се значајан дио одговора не налази у бази, онда овај приступ није адекватан, и више ће да створи проблема него што ће да буде користан.
Специфичне трансформације
Сада је вријеме да се вратимо на поље mask споменуто у примјеру. Захтјев који није ријешен у примјеру је да се детаљи из документа могу маскирати по неком предефинисаном шаблону, а који је смјештен у том пољу. Да ли то значи да треба да одбацимо све урађено и вратимо се на стари начин, због једне мање трансформације? Не нужно. Трансформација коју је потребно извршити је релативно једноставна, нема тзв. бочних ефеката, и може се лако написати као PL/pgSQL функција:
create or replace function mask_detail(mask text, v text)
returns text
language plpgsql
immutable
parallel safe
returns null on null input
as
$$
declare
output text;
len int;
begin
output = trim(v);
len = length(output);
case mask
-- mask middle text
when 'abc***xyz' then
case
when len > 6 then
output = substring(output, 1, 3) || '***' || substring(output, len - 2, 3);
when len = 6 then
output = substring(output, 1, 1) || '***' || substring(output, len - 1, 2);
when len > 1 then
output = substring(output, 1, 1) || '***' || substring(output, len, 1);
when len = 0 then
output = '';
else
output = substring(output, 1, 1) || '***';
end case;
-- other cases omitted for clarity
else
return output;
end case;
return output;
end;
$$Сада подупит за детаље документа може да изгледа овако:
select json_agg(json_build_object(
'name', dd ->> 'name',
'value', mask_detail(dd ->> 'mask', dd ->> 'value')
)) from jsonb_array_elements(d.details) ddСве ово значи да ће можда бити потребно да се и одређени дио кода, а који је уско везан за податке, пребаци у слој базе података (а са којим се управља кроз систем миграција, као и са табелама), а не само креирање одговора кроз упит. Ова идеја тешко ће да легне некоме коме се не допада да има логику ”разбацану на више мјеста”.
Са друге стране, није неуобичајена појава да нека апликација функционише као низ одвојених сервиса задужених за различите ствари, па би PostgreSQL могао да се посматра као засебан сервис са којим се комуницира преко RPC API-ја, а који умјесто protobuf или JSON формата парсира SQL.
Динамички упити
Разумно питање у овом моменту би било: Како динамички да креирам упите? Немој ми рећи да сад треба да спајам SQL стрингове као у раним данима PHP-а?
Креирање упита спајањем стрингова заиста јесте лоше рјешење - читљивост је лоша и погодно је тло за грешке. Како смо установили да ORM није опција, шта нам друго преостаје? Пошто су сада упити нешто дужи него иначе, рјешење које ћу да предложим је исто оно које су људи измислили како не би користили спајање стрингова за генерисање HTML кода: шаблонски језик.
То може да буде било који шаблонски језик са сљедећим особинама:
- Има синтаксу која је лако уочљива у тексту. Они засновани на великим заградама би требало да одговарају.
- Брзо се парсира, или има механизам за кеширање, како би се једном парсирани шаблон могао да користи више пута.
Испробао сам овај начин са Go-овим text/template и ембедовањем фајлова помоћу embed директива, и за сада ми није одбојан (мада волио бих да постоји боља подршка за едитор). Напомињем да није потребан Go за ово, може се пробати нешто слично са шаблонским језицима попут Twig, Liquid, Mustache или било ког другог који би могао да одговара.
А како то заправо изгледа може да се види у примјеру испод, гдје су подаци о кориснику везаном за фолдер опциони:
select
json_build_object('data',
json_build_object(
'id', f.id,
'name', f.name,
'settings', json_build_object(
'alert_on_visit', f.settings -> 'alert_on_visit',
'folder_color', f.settings -> 'folder_color'
),
{{if .ShowUser}}
'user_name', u.name,
'user_profile', u.profile,
{{end}}
'external_links', (select json_agg(el - 'id')
from jsonb_array_elements(f.external_links) el)
)
)
from folder f
{{if .ShowUser}}
inner join public.user u on u.id = f.user_id
{{end}}
where f.id = $1Није идеално, али цијеним да је боље рјешење од спајања стрингова. И при том је на располагању сав подржан SQL, без потребе за ”превођењем”.
Закључак
Презентујући ову идеју, надам се да сам подстакао читаоце на даље истраживање могућности алата које свакодневно користе, како би дошли до рјешења која су једноставнија и/или бржа. Лако је држати се принципа који су “најмањи заједнички именилац”, и менталитета “одувијек радимо на овај начин”, и на тај начин, фигуративно речено, одложити многе корисне ствари на таван да скупљају прашину, јер нисмо сигурни да ли да их користимо. И да, као прави инжењери, пажљиво анализирају исплативост сваке идеје у неком датом контексту.